Please stop stripping our metadata
Regardless of whether proposed orphaned work legislation is a good idea or not, it shouldn’t become law until organizations stop creating new orphaned works every time we upload content.
by Mark Meyer · Posted in: photography business
…but if there were no bad people, there would be no good lawyers.
The U.S Copyright Office has spent years searching for a solution to the problems of orphaned works. Orphaned works are those bits and pieces of creative history that, because of the way the law works, are protected by copyright even through the author is unknown or can't be located. These are works—sound recordings, letters, photographs, essays—that have historical value but are laden with liability for any use that doesn't fit into the paradigm of fair use. In many fields this is a compelling problem, but so far it's been impossible to draft a solution without creating even more problems that provide bad faith actors with a subjective defense of infringement. Despite the failure to pass a bill in recent years, groups like ASMP think orphaned work legislation is inevitable. In hopes of drafting a solution that fixes the problems without crippling current protection, the U.S. Copyright office is once again seeking comments and has extended the deadline until February, 2013. (You can get a sense of the difficulties of this legislation by skimming the Copyright Office's report from 2006 (PDF))
The strongest arguments for orphaned works legislation come from organizations that want to digitize libraries, researcher institutions, and scholars. These are people like the biographer who finds a shoebox full of old, unattributed photos of her subject but can’t identify or locate the photographer. Without the ability to contact the photographer the biographer can’t know the copyright status and therefore can’t publish the photos without exposing herself to significant liability—up to $150,000 per use. The result: it’s not published, the original creator never has the opportunity to profit from the biographer’s interest, and the world is a poorer place because interesting work remains in the shoebox under the bed essentially undiscovered. The inability to locate copyright holders prevents museums from using material in exhibits, documentary filmmakers from including historic recordings, scholars from publishing archives of historic work—and nobody including the original creators of the work benefits.
These arguments have one basic thing in common—they are concerned with older works, works that under previous copyright regimes would have passed into the public domain. The problem that orphaned works legislation is trying fix is a problem that in large part has been caused by the continual extension of copyright protection to the point that even work from the distant past is encumbered with liability and few options to limit it.
Crafting a solution that addresses old, mostly-forgotten works without jeopardizing the livelihood of active creatives has proven elusive. The proposed legislation effectively removes the powerful liability that puts teeth into copyright laws so long as users can assert in good faith that they tried and failed to locate the author. This is especially problematic for photographers because the tools for working backward from an image to its creator are still immature. Google images only gets you so far.
The truly disheartening part of this story is that there is no reason for work created today and distributed digitally to ever become orphaned in the first place. These aren’t prints in a shoebox under a bed; they are digital files that can easily carry metadata including the author’s contact information with them everywhere they go.
The Promise of Metadata
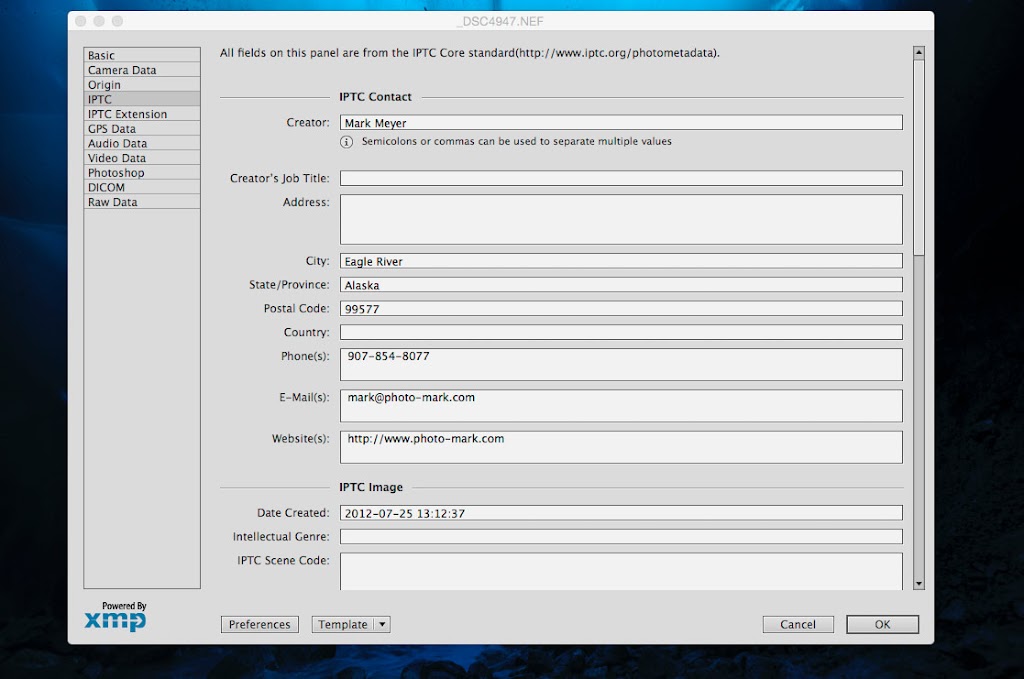
There is not a single file format in standard use that does not make provisions for tagging the work with information about the author, photographer, composer, artist, or publisher. Jpegs, the standard file format for photographs on the web, are easily tagged with the photographer's name, contact information, release and copyright status, as well as full host of caption and location data. This information rides along with the image, it is generally invisible to the viewer, but it is available to anyone who needs it through all standard software. Because the image and the metadata stick together in one convenient package we should, in theory, no longer worry about our work becoming separated from us and falling into the creative orphanage where this legislation may remove significant copyright protections.
Even Apple's Preview App will display image metadata
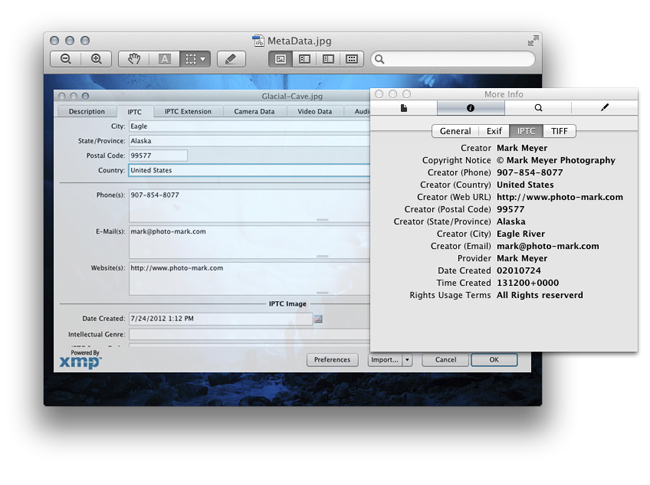
But here’s the problem: It is standard practice to strip this metadata from images. Upload an image to Facebook and Facebook wipes all contact and copyright information clean. Twitter does the same thing. This becomes very frustrating when you have an image that catches on, gets passed around in ways that you as a copyright holder may not mind, but ends up on servers all over the world with no metadata pointing back to you. These services that provide some of the most-used tools for sharing content are creating millions of potentially orphaned works every day. And there is no reason for it—the tools to preserve metadata are ubiquitous and easy to use.
A Case Study
Here’s an example from someone who should know better, National Geographic. They recently finished their annual photography contest, one of the most popular contests in world that attracts professional and amateur photographers from around the world with the promise not only of prizes, but serious exposure for photos that the editors choose to highlight. But when they publish the images, the metadata is stripped. This in itself doesn’t orphan the images—they provide a caption that includes the photographers name (although not contact information). But unlike metadata within a file, a caption adjacent to an image does not travel with it.
So the work begins to get picked up and spread around:
First by major outlets
The Atlantic
MSN
Yahoo News
And then the blogs pick it up:
thisiscolossal.com
FStoppers
At some point they stop attributing the images
izismile.com
ewandoo.co
And then the rest of the world:
France |
China |
Armenia |
Vietnam |
Iran |
Russia |
Slovakia
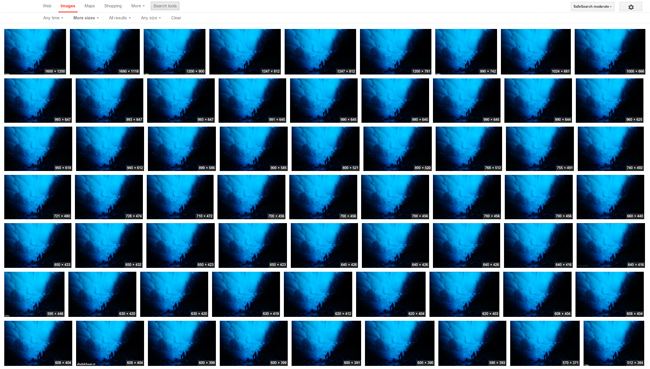
In the course of a couple days this image went from an annotated jpeg with my complete contact information to a bunch of unattributed files scattered all over the world with no metadata whatsoever. In National Geographic's defense, this is probably unintentional. Many of the basic tools that automatically process images on web servers strip metadata by default. If you're not paying attention you can lose this information by simply resizing a photo.
Google Image Search after a couple days—all without any metadata pointing back to the photographer.
This shouldn’t happen
If we are going to have orphaned works legislation that removes liability for using copyrighted work when the author cannot be found, we should include language that compels organizations that traffic in content like Facebook and Twitter to keep metadata intact. Give it some teeth and allow copyright owners to go after organizations that strip authorship information from their work. We should also encourage developers who write the tools for manipulating content to make preserving metadata the default. It should require an active, intentional act to strip metadata from digital files. We should also encourage developers of viewing software like web browsers to make it easier to access this metadata. Wouldn’t it be nice it you could hover over an image in your web browser and get a tool-tip with the photographer's name and website? And, of course, we as photographers need to understand the tools and remember to save metadata with files destined for the web. It won't fix all the problems with the legislation, but it is a sensible and important step to prevent new work from becoming orphans for no reason. If you have other ideas, please consider submitting a comment to the copyright office before February.